Codex/ClaudeCode/Codebuddy使用Headroom压缩
潘忠显 / 2026-06-08
前文介绍了用于压缩 Agent 上下文内容的 Headroom。我在刚安装完 headroom-ai[all] 之后,以为只要把 Headroom MCP 装上,Agent 就会自动使用它的压缩能力。后来实际验证发现,这个理解是错误的。
MCP 装上之后,只是多了一组 Agent 可以主动调用的工具,例如压缩、取回和查看统计。它并不会天然改变 Codex UI 和 OpenAI API 之间的请求路径。也就是说,如果 Codex UI 的模型请求仍然是直接发往 OpenAI API,那么 Headroom 其实没有机会在中间做自动压缩。
真正要让压缩生效,关键不是“装了 MCP”,而是让 Codex UI 的请求经过 Headroom proxy。
本文将介绍 Codex UI、使用第三方 Token Plan 的 Claude Code,以及 CodeBuddy 应该如何使用 Headroom。
Headroom 的实际工作原理
默认情况下,Codex UI 的请求链路大致是:
Codex UI -> OpenAI API
接入 Headroom 之后,目标是变成:
Codex UI -> Headroom proxy -> OpenAI API
这样 Headroom 才能在请求发往 OpenAI 之前,对上下文、工具输出或历史内容做压缩处理,然后再把优化后的请求转发给真正的 OpenAI API。
所以这里有两个角色需要区分。
headroom proxy 是真正参与请求链路的部分。它负责接收 Codex UI 的 API 请求,执行压缩和统计,再转发到后端模型服务。
headroom mcp 则更像是辅助工具入口。它可以让 Agent 在看到压缩标记时主动调用 headroom_retrieve 取回原文,也可以主动使用压缩或统计工具。但如果没有 proxy,MCP 本身不会自动拦截 Codex UI 的模型请求。
一句话概括就是:MCP 让 Agent 能主动用 Headroom 工具,proxy 才让 Codex UI 的请求自动经过 Headroom。
Codex 的配置方法
首先需要启动 Headroom proxy。
source ~/.venvs/headroom/bin/activate
headroom proxy
如果已经安装在其他 Python 环境里,就把第一行换成对应环境的激活命令,让 headroom proxy 跑起来。然后修改 ~/.codex/config.toml,设置 openai_base_url 让 Codex UI 的 OpenAI 请求走这个 proxy。
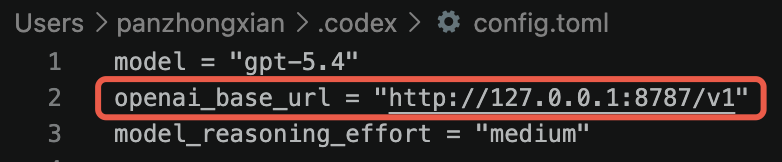
这里最关键的是:
openai_base_url = "http://127.0.0.1:8787/v1"
它的含义是:Codex UI 仍然使用 OpenAI provider,但请求先发到本机的 Headroom proxy,再由 Headroom 转发给 OpenAI API。
改完配置之后,需要重启 Codex UI。更稳妥的顺序是:
- 先启动
headroom proxy - 再打开或重启 Codex UI
- 在 Codex UI 里正常对话
- 查看 Headroom stats,确认请求和压缩数据有变化
查看统计可以用:
curl -s http://127.0.0.1:8787/stats
如果对话之后看到类似这些统计值增加,就说明请求确实经过了 Headroom:
api_requests: 14
requests_compressed: 16
proxy_compression_saved: 54420
这次验证时,proxy_compression_saved 从 8846 增加到了 54420,说明 Codex UI 的请求已经走过 Headroom proxy,并且压缩确实生效。
后面继续对话后,又看到一组更完整的统计:
input: 3356228
output: 17323
saved: 69435
proxy_compression_saved: 69435
如果粗略按输入 token 来算,69435 / 3356228 大约是 2.07%。这说明压缩确实生效了,但在这类文章写作和精修场景里,收益不会像大量日志、工具输出或代码检索那样夸张。因为写作任务本身更依赖原文细节,压缩策略通常也不应该过于激进。

容易踩的坑
别把 Codex 的 provider 直接改成 headroom。例如这种配置:
model_provider = "headroom"
openai_base_url = "http://127.0.0.1:8787/v1"
从“让请求走 Headroom”的角度看,这种写法看上去很合理,但在 Codex UI 里可能带来一个副作用:历史会话突然变空。
这不是历史数据真的丢了,而是 Codex UI 的本地会话表里有 model_provider 字段。原来的历史会话通常属于 openai provider;如果配置里把当前 provider 切成了 headroom,UI 就可能只显示 headroom provider 下的会话。于是看起来像是历史没了。
这次更稳的做法是:**不要设置 model_provider = "headroom",只设置 openai_base_url。**也就是保留 Codex UI 对 provider 的理解,provider 仍然是 OpenAI,但把 OpenAI base URL 指向 Headroom proxy。
这样可以同时满足两个目标:历史会话仍然正常显示,Codex UI 的模型请求仍然经过 Headroom proxy。
Claude Code + 第三方模型的配置方法
类似的问题在 Claude Code 使用第三方模型时也会出现。比如开发机上的 Claude Code 使用的是阿里云 Token Plan,原本可以直接把 Claude Code 的 ANTHROPIC_BASE_URL 指向阿里云 endpoint:
Claude Code -> 阿里云 Token Plan
但接入 Headroom 之后,请求链路应该变成:
Claude Code -> Headroom proxy -> 阿里云 Token Plan
这时只给 Claude Code 改 ANTHROPIC_BASE_URL 就不够了。Claude Code 需要指向本机 Headroom proxy,而 Headroom proxy 自己也要知道最终上游是阿里云 Token Plan。
所以配置会分成两层:
- Claude Code 的
ANTHROPIC_BASE_URL指向本机 proxy,例如http://localhost:8787 - Headroom proxy 启动时指定真正的上游地址,也就是阿里云 Token Plan endpoint
启动 proxy 时可以用参数方式:
source ~/.venvs/headroom/bin/activate
headroom proxy \
--port 8787 \
--backend anthropic \
--anthropic-api-url "https://token-plan.cn-beijing.maas.aliyuncs.com/apps/anthropic"
也可以用环境变量方式:
source ~/.venvs/headroom/bin/activate
export ANTHROPIC_TARGET_API_URL="https://token-plan.cn-beijing.maas.aliyuncs.com/apps/anthropic"
headroom proxy --port 8787 --backend anthropic
然后让 Claude Code 指向本机 proxy。比如在 /root/.claude/settings.json 中配置:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:8787",
"ANTHROPIC_AUTH_TOKEN": "仍然是阿里云 Token Plan 的 API Key",
"ANTHROPIC_MODEL": "qwen3.6-plus"
}
}
Headroom proxy 只是中间层,请求最终还是会转发到阿里云。验证方式和 Codex UI 类似,先看 proxy 是否正常:
curl -s http://localhost:8787/health
再确认上游是否指向阿里云:
curl -s http://localhost:8787/health | jq '.config.anthropic_api_url'
然后看压缩统计是否增长:
curl -s http://localhost:8787/stats

这里的关键结论是:Claude Code 仍然通过环境变量接入 Headroom,但 proxy 也需要通过 --anthropic-api-url 或 ANTHROPIC_TARGET_API_URL 知道最终要转发到阿里云 Token Plan。否则就可能出现两种问题:要么 Claude Code 绕过 Headroom 直连阿里云,要么 Headroom proxy 按默认上游去请求 Anthropic 官方 API。
CodeBuddy 使用 Headroom 的边界
前面已经梳理清楚了两种能走通的模式:Codex UI 可以改 openai_base_url,Claude Code 也可以通过 ANTHROPIC_BASE_URL 接入第三方 API。理解了这两种模式,就更容易看出 CodeBuddy 的边界。
CodeBuddy 不是完全不能使用 Headroom proxy,而是要区分两种情况:第三方自定义模型可以尝试接入 proxy;CodeBuddy 内置模型无法按这种方式接入 proxy。
CodeBuddy 内置模型,比如内置的 Opus 4.6,通常不是直接访问用户可控的 OpenAI 或 Anthropic API,而是走 CodeBuddy 自己的后端:
CodeBuddy IDE -> CodeBuddy 后端 -> 模型
这条链路的问题在于,我们拿不到内置模型实际使用的 base URL 和 key。公开文档里能看到的是用户自己配置 endpoint/key 的方式,而不是把内置模型的默认地址和凭证暴露出来让用户改成本机 proxy。即使知道了某个后端 URL,也不一定能直接转发,因为 Headroom proxy 支持的是标准 OpenAI/Anthropic 这类 API 协议,而内置后端可能还有自己的鉴权、协议或 IDE 内部逻辑。
但这并不是说 CodeBuddy 不能配置第三方模型。公开资料里能看到 CodeBuddy 支持通过 OpenAI Compatible、models.json、CODEBUDDY_BASE_URL 等方式配置用户自己的模型 endpoint、API Key 和模型名。如果用这些方式接入 OpenRouter、阿里云 Token Plan 或其他兼容服务,就可以让 CodeBuddy 把请求先发到 Headroom proxy。
这里仍然是两层配置:CODEBUDDY_BASE_URL 或 models.json 里的 URL 是给 CodeBuddy 看的,负责把请求送进本机 proxy;Headroom 自己还需要通过 --openai-api-url、--anthropic-api-url 或对应环境变量知道真正上游在哪里。Headroom 不会因为你设置了 CODEBUDDY_BASE_URL,就自动把它当成自己的上游地址。
所以,如果使用 CodeBuddy 内置模型,目前更现实的方式是 MCP 工具模式:Agent 在处理大量工具输出、长文件或中间内容时,主动调用 headroom_compress 压缩,需要原文时再用 headroom_retrieve 取回。MCP 能提供主动工具调用,但不能让内置模型请求自动经过本机 proxy。
简单总结一下:
- CodeBuddy 内置模型: 拿不到默认 base URL/key -> proxy 自动压缩走不通
- CodeBuddy 自定义模型: 可以把自定义 URL 指向 proxy -> 需要同时配置 Headroom 的真实上游
哪些场景要谨慎使用
Headroom 的压缩能力很适合长上下文工程任务,比如读大量代码、日志、搜索结果或工具输出。这些内容通常体量大、重复多,而且需要时还可以重新读取文件或通过 retrieve 取回原文。
但有些场景要更谨慎。比如精修文章、合同、提示词、需求文档这类任务,产物质量高度依赖原句细节。如果关键文本被压缩成摘要,Agent 后续继续修改时,可能只看到概括,不再看到完整措辞,进而影响语气、节奏或细微表达。
所以在写作类任务里,更稳的做法是:可以让 Codex UI 继续走 Headroom,但每次改正文前都重新读取目标 Markdown 文件,而不是只依赖对话历史里的压缩摘要。
如果正在做非常敏感的逐句校对,也可以临时关闭 Headroom,等精修完成后再打开。
如何临时关闭
临时关闭时,不建议只停掉 headroom proxy。因为如果 ~/.codex/config.toml 里仍然保留了 openai_base_url = "http://127.0.0.1:8787/v1",Codex UI 还是会继续把请求发到本机 proxy 地址;这时 proxy 不在,反而可能导致请求失败。
更稳的方式是把这一行先注释掉:
# openai_base_url = "http://127.0.0.1:8787/v1"
然后重启 Codex UI。这样请求链路会回到默认状态:
Codex UI -> OpenAI API
需要重新开启时,再把注释去掉,先启动 headroom proxy,再重启 Codex UI:
openai_base_url = "http://127.0.0.1:8787/v1"
小结
本文最开始要解决的是一个误解:安装 Headroom MCP,并不等于 Vibe coding 工具会自动使用 Headroom 的压缩能力。MCP 只是提供主动调用的工具,真正能让上下文自动经过压缩的是 proxy,也就是把模型请求链路改成:
工具 -> Headroom proxy -> 真实模型 API
围绕这个判断,本文分别梳理了几种常见工具的接入方式。
Codex UI 可以通过 openai_base_url 指向本机 Headroom proxy,但不要把 model_provider 改成 headroom,否则历史会话可能因为 provider 维度不同而不可见。
Claude Code 使用第三方 API,比如阿里云 Token Plan 时,则是两层配置:Claude Code 的 ANTHROPIC_BASE_URL 指向本机 proxy,Headroom proxy 再通过 --anthropic-api-url 或 ANTHROPIC_TARGET_API_URL 指向真正的阿里云 endpoint。
CodeBuddy 要区分内置模型和自定义模型。内置模型的默认 base URL 和 key 不对用户暴露,所以本机 proxy 无法自动接管;如果使用 models.json 或 CODEBUDDY_BASE_URL 配置的是第三方自定义模型,则可以尝试让 CodeBuddy 指向 Headroom proxy,同时给 Headroom 配好真正上游。
所以最终判断一个工具能不能使用 Headroom proxy,关键不在于它是否支持 MCP,而在于两个问题:第一,能不能把这个工具的模型请求改到本机 proxy;第二,Headroom proxy 能不能知道并兼容真正的上游 API。
配置完成后,再通过 /stats 观察 api_requests、requests_compressed 或 proxy_compression_saved 是否增长,才能确认它是真的生效。