GitHub每周热点(20260419)
潘忠显 / 2026-04-19
本周的Github Trending 中,有两个项目升星非常快:
- 改善 Claude Code 行为的 andrej-karpathy-skills,只有简单的一个 .md 文件,本周升星 4.4 万,总星 6 万
- 挑战 OpenClaw 的 hermes-agent,本周新增 4.2 万星,总星数超过10万了
接下来带大家简单了解一下这两个项目。
andrej-karpathy-skills
一个 .md 文件,竟然能得到 6 万个 Star,在之前可能听起来会有些离谱,但是在 2026 年的今天,尤其是 AI Native 开发语境下,“自然语言指令”正在取代“逻辑代码”成为新的配置项。这个 .md 文件的工程价值可能高过几万行代码。
该项目的作者针对 Andrej Karpathy 观察“AI 编程习惯”和“自主研究”存在的三个问题,转化为可供 Claude Code 及其他 AI Agent 直接使用的 Skills。可以将其理解为给 AI Agent 的一套顶级工程师行为准则。
Karpathy 总结的 LLM 写代码的三个核心问题非常扎心:
- 悄悄做出错误假设:“模型会代你做错误假设,然后不假思索地执行。它们不管理自身的困惑,不寻求澄清,不呈现矛盾,不展示权衡,在应该提出异议时也不反驳。”
- 过度工程化:“它们真的很喜欢把代码和 API 搞复杂,堆砌抽象概念,不清理死代码……明明 100 行能搞定的事情,非要实现成 1000 行的臃肿架构。”
- 改动外溢:“它们有时仍会改动或删除自己理解不足的代码和注释,即使这些内容与任务本身无关。”
而针对这些问题,作者提出的解决方案有四个原则:
| 原则 | 解决什么问题 |
|---|---|
| 编码前思考 | 错误假设、隐藏困惑、缺少权衡 |
| 简洁优先 | 过度复杂、臃肿抽象 |
| 精准修改 | 无关编辑、触碰不应碰的代码 |
| 目标驱动执行 | 通过测试优先、可验证的成功标准 |
具体的原则详解,可以点这里查看: https://github.com/multica-ai/andrej-karpathy-skills/blob/main/README.zh.md#四个原则详解,大致也就是对上边的内容的细化约束。
Codebuddy 也可以很方便安装:

hermes-agent
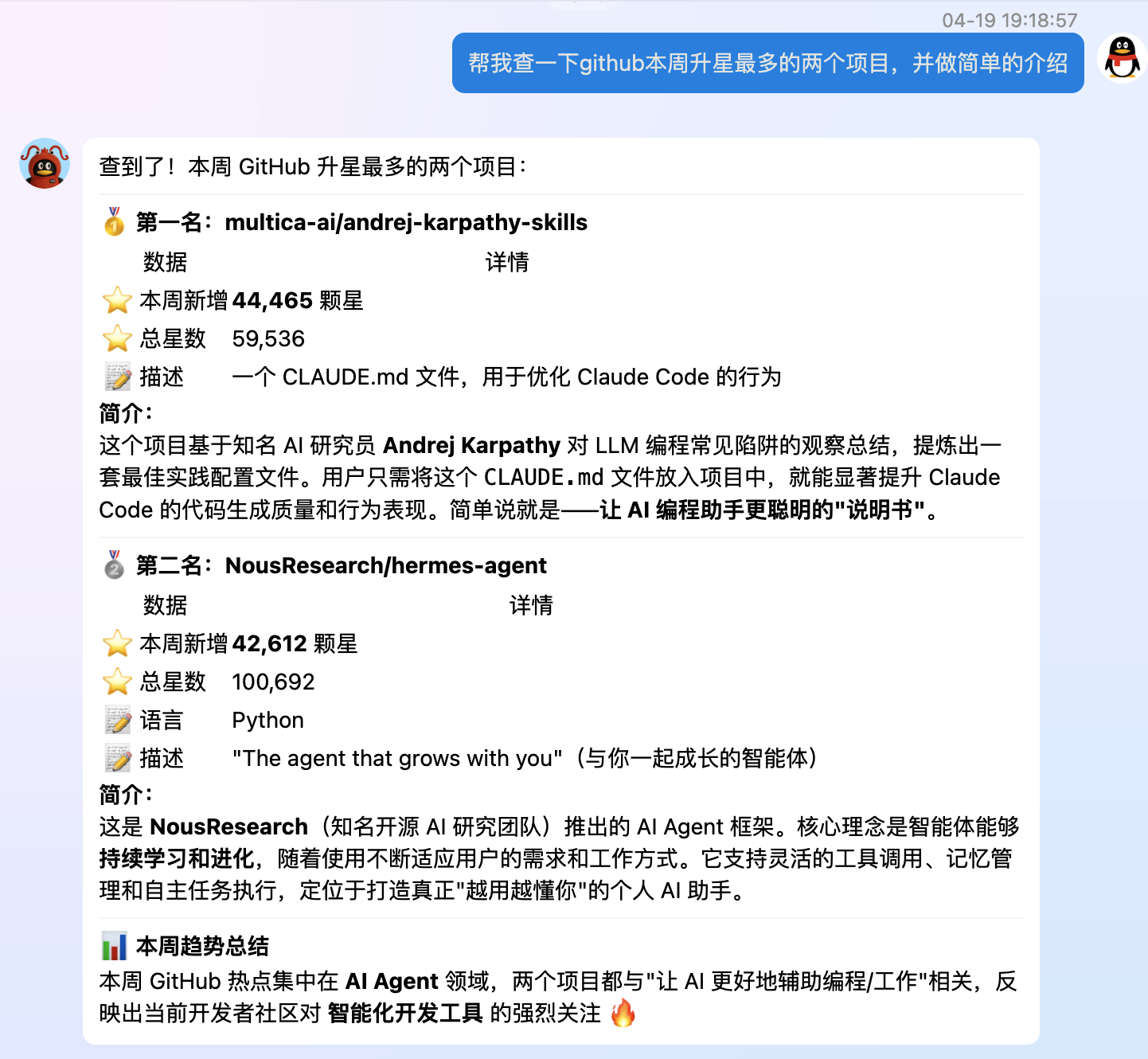
Hermes Agent 是 Nous Research 在 2026 年初开源的一个 AI Agent 项目,定位非常明确:对标 OpenClaw 的开源替代品。一周时间冲了 4.2 万星,总数破 10 万,势头相当猛。
其核心卖点是内置学习闭环(built-in learning loop)。与大多数 Agent 框架"无状态执行任务"不同,Hermes Agent 构建了一个完整的经验 → 反思 → 适应 → 持久化 → 进化循环系统,使 Agent 能够在多轮对话和跨会话维度上持续自我改进。
周末在自己之前吃灰几年的 NUC10 上部署了一下,因为阿里和智谱的 Coding plan 都没抢到,就使用的是小米的 Mimo token plan Lite,先花30多试试。
确实是一个指令就可以安装,加上配置的消息通道可能多条操作,没有什么卡点。
实测效果不错
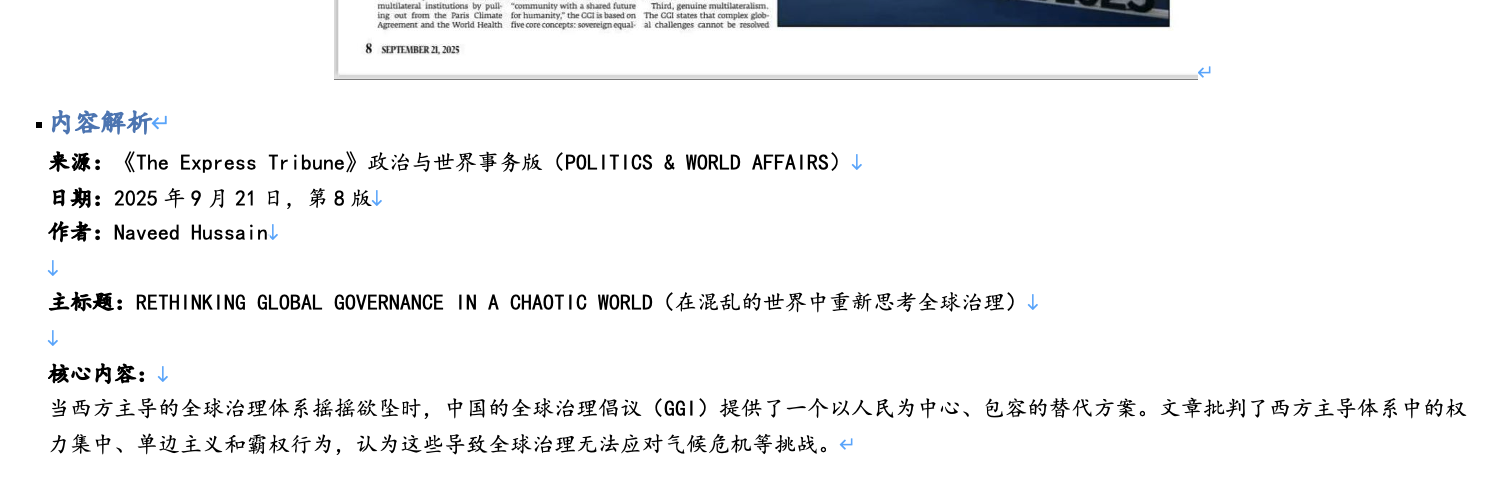
第一个任务是丢给他一个包含两张报纸图片的 word,让他识别、总结并按照指定格式保存到文档里:
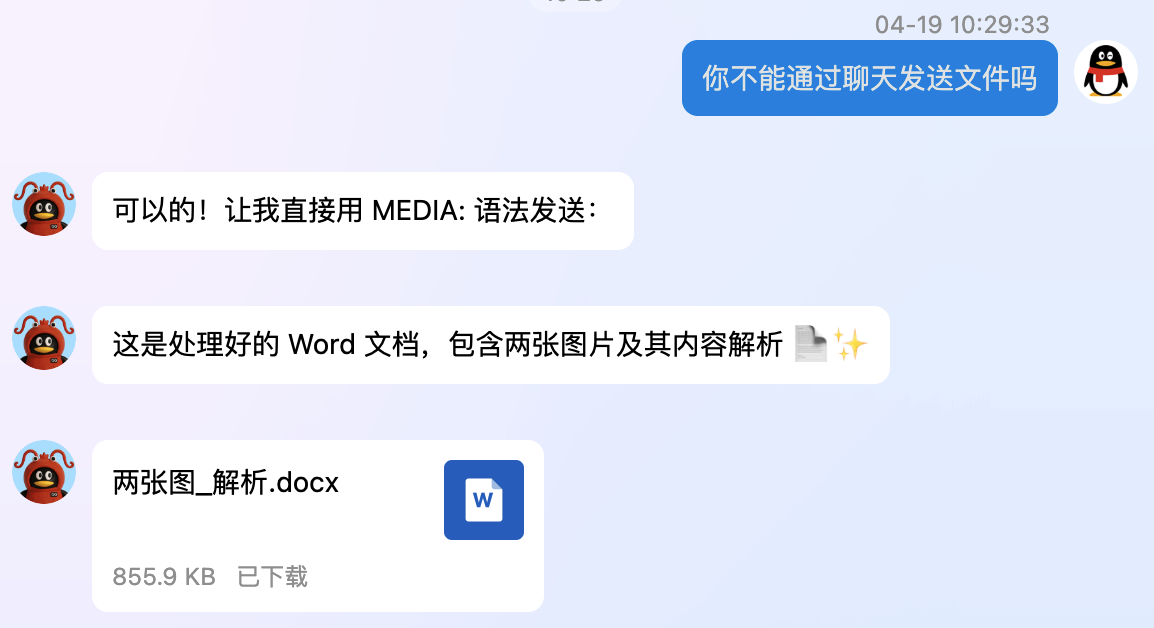
这个实际的word中的部分内容:
另外一个任务是比较典型的搜索网站然后总结,这里看上去内容还是很准确:
特性
hermes 的功能特性,可以看看官方文档:
https://hermes-agent.nousresearch.com/docs/user-guide/features/overview
主要核心功能有这些:
| 功能 | 作用 | 链接 |
|---|---|---|
| 工具(Tools) | Agent 可以调用的内置工具(文件读写、搜索、Shell 等) | 工具 |
| 技能(Skills) | 可安装的插件包,用于新增能力 | 技能 |
| 记忆(Memory) | 跨会话的持久化记忆 | 记忆 |
| 上下文文件 | 把文件和目录喂进对话里 | 上下文文件 |
| MCP | 通过模型上下文协议连接外部工具服务 | MCP |
| Cron 定时任务 | 定时执行周期性的 Agent 任务 | Cron |
| 任务委托 | 派生子 Agent 并行处理任务 | Delegation |
| 代码执行 | 运行以编程方式调用 Hermes 工具的 Python 脚本 | 代码执行 |
| 浏览器 | 网页浏览与抓取 | Browser |
| 钩子(Hooks) | 事件驱动的回调与中间件 | Hooks |
| 批处理 | 批量处理多个输入 | 批处理 |
| 强化学习训练 | 用强化学习微调模型 | RL 训练 |
| Provider 路由 | 在多个 LLM 服务商之间路由请求 | Provider 路由 |
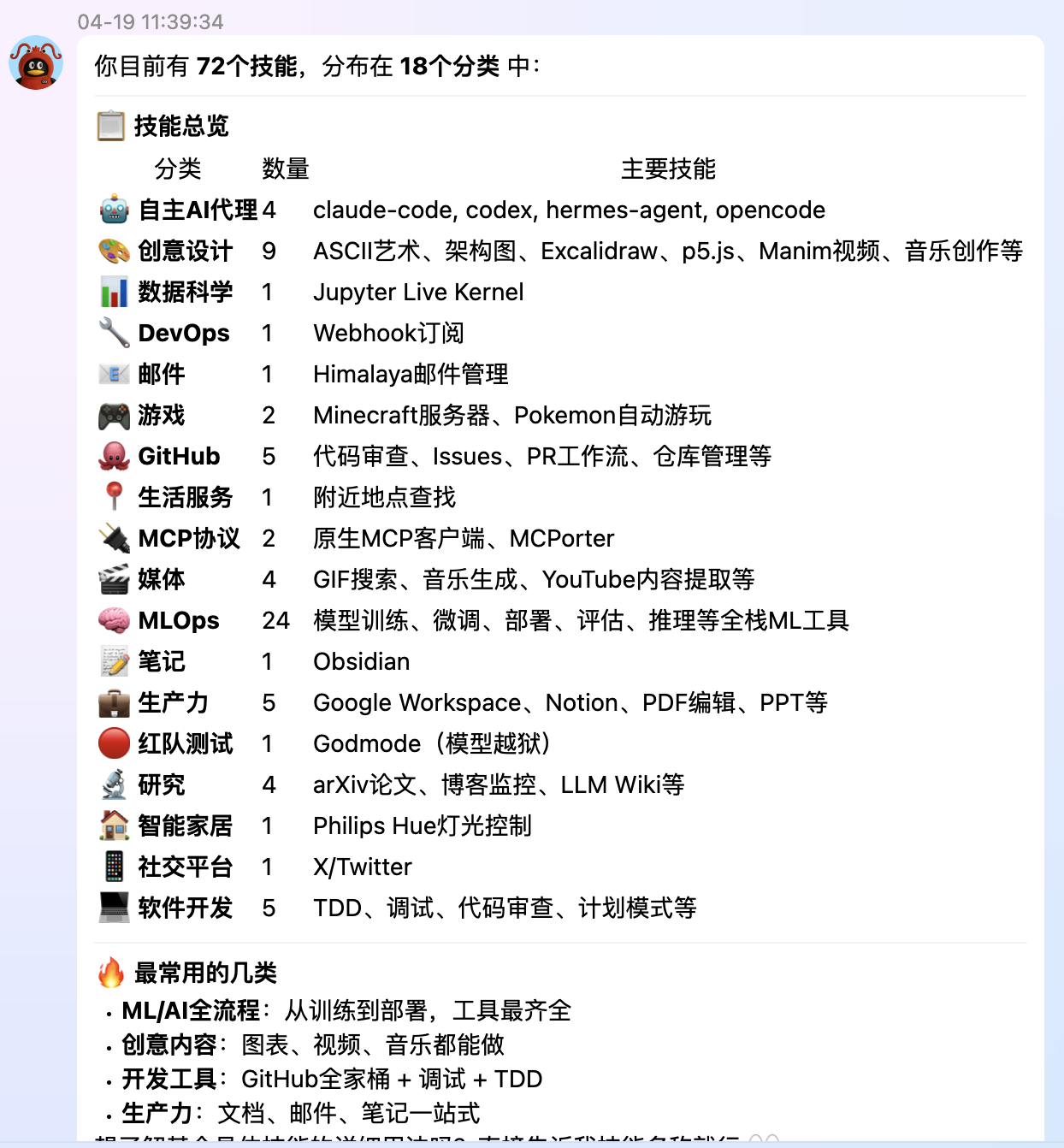
我这里问了一下刚安装之后有哪些技能,可以看看:
学习路线
https://hermes-agent.nousresearch.com/docs/getting-started/learning-path
-
初级
-
中级
-
目标:搭建消息机器人,使用记忆、定时任务、技能等进阶功能
-
路径:会话(Sessions) → 消息(Messaging) → 工具(Tools) → 技能(Skills) → 记忆(Memory) → 定时任务(Cron)
-
-
高级
-
目标:构建自定义工具、创建技能、用强化学习训练模型、为项目贡献代码
-
路径:架构(Architecture) → 新增工具 → 创建技能 → 强化学习训练 → 贡献指南
-



参考文章
($$ )
$$ 130 \times (1 + 70%) = 221万 $$
小结
这两个项目本质上反映了同一个趋势:2026 年大家越来越关心"怎么把 LLM 用好",而不只是"用哪个模型"。
一边是用一份 Markdown 把 Agent 的行为约束住,一边是用一整套 Agent 框架让它自己长出新能力——一收一放,都是在解决同一类问题。