Agent 如何使用大模型和工具
潘忠显 / 2026-03-30
Agent 如何使用大模型和工具
前段时间,把自己手头的机器人做了一个整理,接入了大语言模型。
原来的机器人,需要这样 lol clear_cache openid uid 类似的方式使用严格的指令来调用工具。
接入大语言模型之后,有几个明显的便利:
- 不需要记业务缩写和指令
- 一次对话可以支持多个命令的调用
- 利用回话历史不需要每次重复背景
比如下边这个回话,在前面我是告诉他了哪个活动,然后让其清理缓存。工具中我只写了一个清理单个缓存的函数,但是 ReAct 模式能够利用大模型把 3 组帐号都清理掉。

而如果缺少信息,也可以通过多轮回话要求补充:
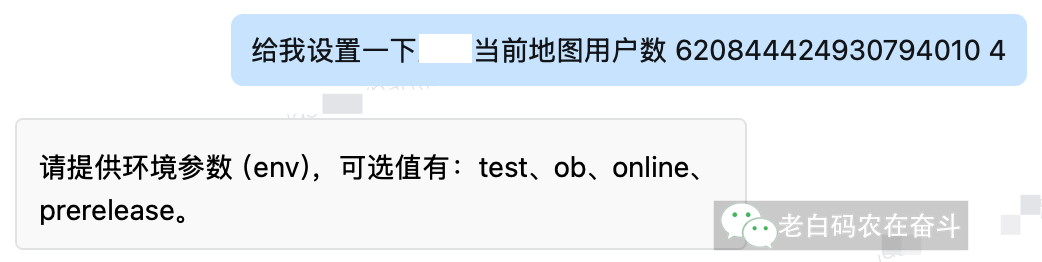
借着这个改造,给大家介绍一下 Agent 到底是如何利用大模型的。
改造成本
因为原来使用自己写的框架 wecom-bot-svr,入口是一个 handle_command() 的函数,输入的内容会在这个函数中进行路由到不同的工具上。
而原来的工具也比较规整的按照业务存放了文件、按照命令定义了函数,这样非常方便改造
这个改造任务我直接让 Cursor 去完成的,改造完之后的结果就是,多了以下 3 部分:
- 抽象出工具注册层:自动发现 cmd_* 函数并生成标准 tool schema。
- 抽象出工具执行层:统一按 tool_name + arguments + user_id 做函数定位、权限校验和执行。
- 增加自然语言工具调用链路:在消息处理流程中引入基于 LLM tool calling 的多轮执行机制。这套实现更接近“LLM function calling/tool calling 循环”,可以类比 ReAct,但不算那种完整显式的 Thought/Action/Observation 的 ReAct Agent。
- 增加会话级历史管理,多轮对话可以继承上下文,不是一次性单轮调用。
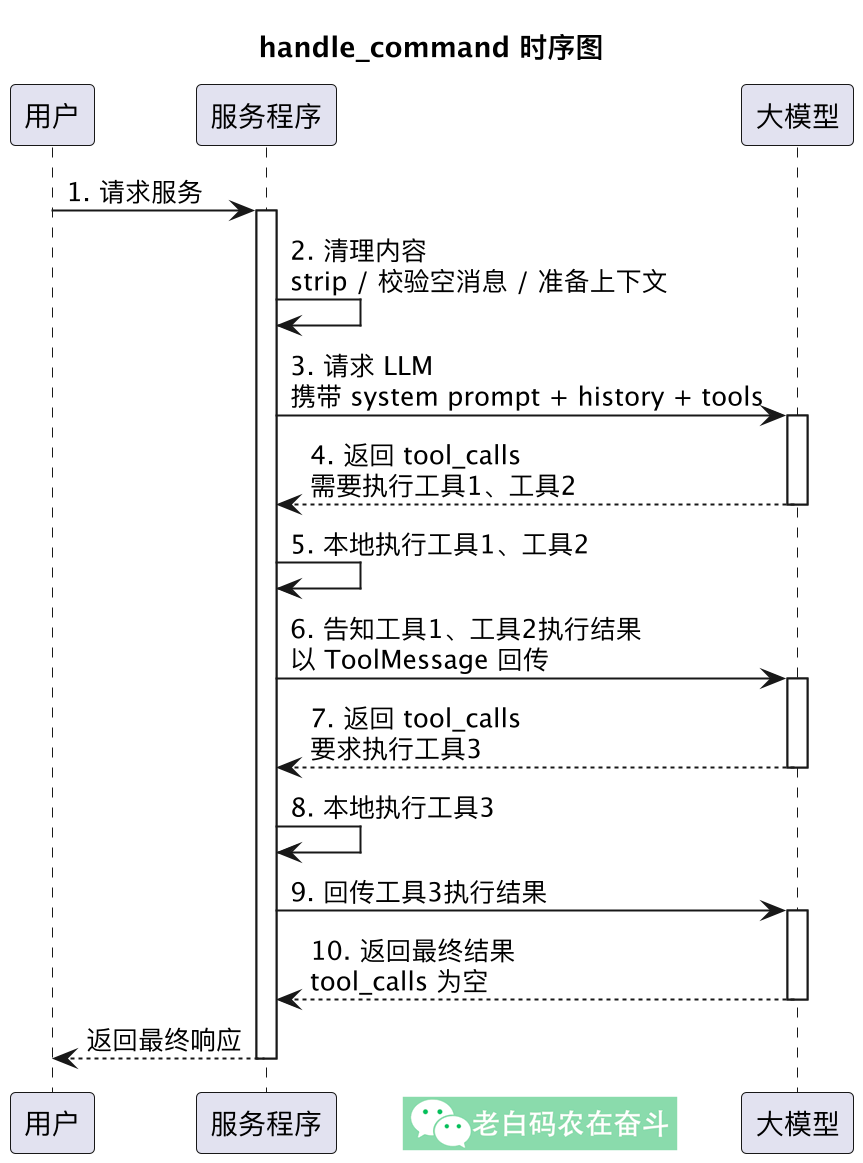
这里简单的把第 3 条里 handle_command 的 Tool Calling 循环部分,画一个时序图表示一下:
大语言模型的作用
这里边大语言模型到底起到什么作用呢?大模型是「脑子」:
- 意图解析:将自然语言翻译成“结构化协议”,将人的意图映射为已经定义好的
tool schema(结构化 JSON),包括查找到合适的指令、通过清洗、转换得到合适的参数(比如你说「今天」,它也能转换成命令需要的20260330的格式)。 - 要求补充信息,前面的例子中也展示了,如果函数描述不清或者缺少参数,也可以通过多轮交互进行补充。
- 提取历史对话中的有用内容,是多轮对话逻辑自洽。
- 任务编排:这是 ReAct(推理-行动)循环的威力。模型在判断当前状态时,发现用户提到了多个对象,它会连续输出多组 Tool Call 请求。
- 汇总结果:当所有工具数据都返回后,它负责把零散的原始数据(如 JSON 或数值)加工成人类能听懂的自然语言。
大模型知识一个脑子,脑子是不直接使用工具的——只判断应该使用哪个工具,大模型并不具备执行工具的能力!
想清楚这点也很容易:首先,你告诉大模型的只有工具名和描述;其次,工具的调用肯定是在你服务器的环境才能运行的。
什么是 ReAct 模式
ReAct 模式由 Google 在 2022 年提出,其核心公式是: 推理 (Thought) + 行动 (Action) + 观察 (Observation) = 下一步决策
一个简单的例子:
Task: 今天天气怎么样
Thought: 模型分析用户的需求,意识到自己不知道位置,于是决定:“我需要先调用获取位置的工具”。
Action: 调用 `get_location` 工具
Observation: 获取工具返回的结果(例如:深圳)
Thought: 模型拿到深圳后,再次思考:“现在我有位置了,我需要调用天气工具来获取深圳的天气”。
Action: 调用 `get_weather(深圳)` 工具。
Observation: 获取深圳天气数据下雨
Thought: 我已经得到了所需的信息
Action: finish(answer="深圳今天会下雨")
通过伪代码,我们在此理解一下这里的 ReAct 模式:
# 简化版 Agent 循环逻辑
while not final_answer:
# 1. 将对话历史和提示词发给 LLM
response = llm.predict(prompt + history)
# 2. 解析 LLM 的输出 (解析出 Thought 和 Action)
action, action_input = parser.parse(response)
if action == "Final Answer":
final_answer = action_input
else:
# 3. 执行工具 (Action)
observation = tools[action](action_input)
# 4. 将结果反馈给下一次循环 (Observation)
history.append(observation)
再对照我机器人的代码,可以看看这里的对应上边循环中的各个部分:
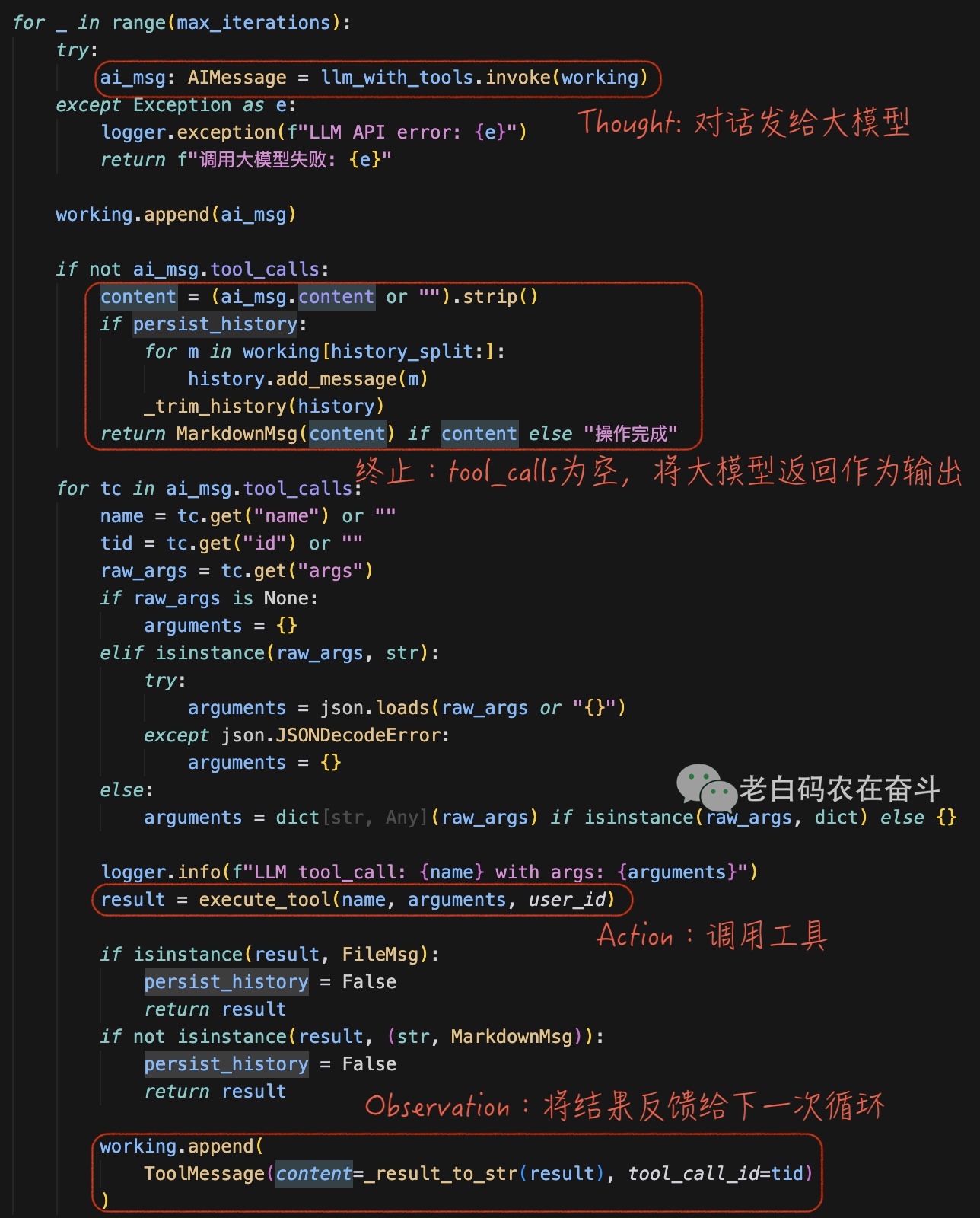
这个简单的循环,能解决很多很多的问题,只要 tools 和 给的信息足够。
即使不够,大模型也会在第二个框处终止,要求更多的信息。
回到最初的问天气的例子,如果问的是「北京天气怎么样」,上边的循环就会跳过调用查询位置,直接调用查询天气。
更简单的 ReAct 实现
上边那个循环,实际是实现了 langchain 中的 AgentExecutor 概念,也就是使用 AgentExecutor 直接简化掉前面的 for 循环:
# 创建 Agent 执行器(替代那个控制循环)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 开启 verbose 可以看到 Thought/Action/Observation 的过程
handle_parsing_errors=True # 处理 LLM 输出格式不规范的情况
)
但是,这个AgentExecutor 也被 langchain 废弃了,因为它太像一个“黑盒”,开发者很难干预中间状态。于是就有了 LangGraph 这个库,在该框架中,ReAct 模式被抽象为一个有状态的图 (State Graph):
- 节点 (Nodes):执行具体动作(如 LLM 推理、工具执行)。
- 边 (Edges):决定下一步去哪个节点(如“继续调用工具”或“直接给答案”)。
- 状态 (State):在节点间传递的“记忆”,记录了所有的对话历史和工具调用结果。
上边的这些类型是通过 LangGraph Graph API 来实现的。
但是为了简化线性循环这样简单的场景,langgraph 又分装出了 Functional API,比如这样:
# Functional API 示例 (非常简洁)
from langgraph.prebuilt import create_react_agent
# 这一行代码其实就在底层帮你构建了一个包含 "agent" 和 "tools" 节点的图
app = create_react_agent(model, tools)
前面提到的手动定义边、节点、状态的这种复杂的图,它允许你像画流程图一样精密地控制 Agent 的每一个动作。适用于一些复杂场景:
- 多智能体协作 (Multi-Agent):比如 A 节点是“程序员”,B 节点是“测试员”,C 节点是“部署员”。
- 人工介入:在执行某个危险工具(如删除数据库)之前,必须由人类点击“确认”才能继续。
- 复杂的控制流:比如如果工具连续失败 3 次,则跳转到“报错节点”发送邮件,而不是死循环。
- 长期记忆与持久化:需要精细化管理状态数据库的读写。
小结
搞清楚了 Agent 中 LLM 如何发挥作用,了解了 Agent 工作原理,然后就可以顺利地开发自己的 Agent。
提个思考题,这里为什么不用 OpenClaw 和 Skill?
后边会分享一下 Agent 中多模型协同使用、langchain/langgraph 的一些学习和应用。
欢迎关注。