从ES性能优化到防御性编程
潘忠显 / 2026-03-31
凌晨收到「线上一个推荐服务的,服务耗时明显增加」的告警。

简单排查了一下,发现是存在 ES 慢查询的问题。
本小文简单聊聊针对性的优化,实际工程中该如何做防御性的开发。
日志信息
下边是慢查询日志,这是一个分片上的查询,耗时 223 ms,命中了超过 100 万的文档

服务会同时发起多种查询语句,而慢查询则只集中出现在这一种查询中:
- 过滤条件为 is_high_quality 为 1,只是用 32 条
- 使用
_seq_no作为种子,加一个seed用于计算random_score排序 - 查询
vopenid等 8 个字段
凭经验我们基本上可以判断,是因为 hits 太多的,然后需要对所有的 doc 都计算 randon_score 造成了极大的性能负担。接下来就探究该语句的工作原理。
Query语句分析
这个 query 的功能一句话概括就是「随机找 32 个高质量玩家」。
具体地,最外层有要求返回的个数、返回的字段,主要还是 query 中的内容。query 中只有一个 function_score 意思是自定义打分逻辑,而不是用默认的 BM25 算法。
而 function_score 又有 3 部分:
query: 定义过滤哪些文档有资格参与打分functions: 对过滤出的文档执行以下计算score_mode: multiply: functions 中算出的分数相乘max_boost: 限制分数的最大上限,防止溢出boost_mode: replace:使用 functions 算出的分数替换掉原来 query 的分数
(原始语句中,有很多 "boost": 1.0,用于 Elasticsearch 的打分公式中作为 “权重系数”,1.0 是默认值。为了清晰展示,我这里就把它剔出掉。)

当 is_high_quality="1" 的文档只有几千个时,ES 瞬间就能计算完。但当现在的业务中这个条件命中了 100 万 文档时:
- 内存占用:ES 需要把这 100 万个文档的 ID 拿出来。
- 哈希计算:对这 100 万个文档逐一读取
_seq_no并做哈希运算(即random_score)。 - 排序开销:对 100 万个随机分数进行大排序,选出最高的前 32 个。
通过上边的查询,我们可以看到总的文档数有 600 万左右,6个分片中每个分片处理 100 万个,跟我们前面看到的日志是一致的。
自定义分数的计算
我们查询条件只有一个打分函数:
"random_score": {
"seed": -1092334812,
"field": "_seq_no"
}
Elasticsearch 内部生成的随机分数(_score)大致遵循这样一个伪代码公式:
$$
score = hash(seed + field_value) \times normalization_factor
$$
field的值:比如你的_seq_no是123456。seed:比如你传的-1092334812。- 哈希运算:系统将这两个值拼接在一起进行哈希。
- 结果:乘上一个归一化因子,生成一个 0 ~ 1 之间的浮点数。
根据上边的公式,我们可以得到一个推论:在所有文档没有变化的情况下,如果 seed 不变,每个 doc 对应的分数是固定的,查询出来的结果也是固定的!
使用固定 Seed 的场景,可以用来多次请求中的分页;而使用不同的 Seed,可以得到不同的随机序列,实现换一批的功能。
如果用户 openid + date 的 hash 值作为种子,那么这个人当天查询到的结果就是固定的一个序列,而每个人的结果却是不同的序列。
而我们的实现中,这里直接没有设置 seed,库中会给一个随机数作为 seed。
var q elasticv7.Query = elasticv7.NewBoolQuery().Filter(filters...)
if randomSort {
q = elasticv7.NewFunctionScoreQuery().
Query(q).
AddScoreFunc(elasticv7.NewRandomFunction().Field("_seq_no")).
BoostMode("replace")
}
200ms 处理 100 万文档
尽管我们觉着 200ms 查询时间很长,但是考虑到每次请求需要处理 100 万级别的文档,是不是还会惊叹其效率之高?
在传统的业务代码(如 Go 或 Java 循环)中,处理 100 万个对象可能需要更久,但 Elasticsearch 做了极致的工程优化:
- 数据在内存中: ES 的
_seq_no或数字字段是按列式存储(Column-oriented Storage)存放的。当它计算random_score时,它不是在处理 100 万个沉重的“文档对象”,而是在内存中读取一个连续的数字数组。CPU 读取这种紧凑的数据极快。 - SIMD 指令集加速: 现代 CPU 可以使用 SIMD(单指令流多数据流)一次性处理多个哈希运算。100 万次简单的哈希 + 乘法,对于 3.0GHz 左右的 CPU 来说,纯计算耗时通常在 几十毫秒 级别。
- 全局排序 (Top-K Sorting):尽管算出了 100 万人的分数,但只要选择前 32 个最大值,可以利用一个大小为 32 的最小堆(Priority Queue),速度极快。
多策略组合实现随机性
我们已经理清了前面为了实现「随机取32个高质量玩家」,需要每次处理 100 万文档造成了性能浪费。那该如何优化实现这个目标呢?
随机还是要随机,但是要缩小打分的范围:
- 分桶策略:核心思想是 “预先随机,查询取模”。将用户 doc 分成若干桶,直接随机桶号(类型 keyword),缩小搜索范围。
- 限制候选集的上限:可以加上
terminate_after: 5000这样限制条件,这个限制是针对不同的分片生效的。比如我们这里 6 个分片实际还是会命中 3 万文档。

- 【实测没用】使用 filter 代替 must:目前的
is_high_quality放在must块中,这会可能触发评分计算逻辑,而使用filter不计算得分。实测这里的步骤没有用,个人猜测 ES 这里有优化:评估出这里是使用replace模式覆盖得分,所以在must的时候也不会计算这个开销。
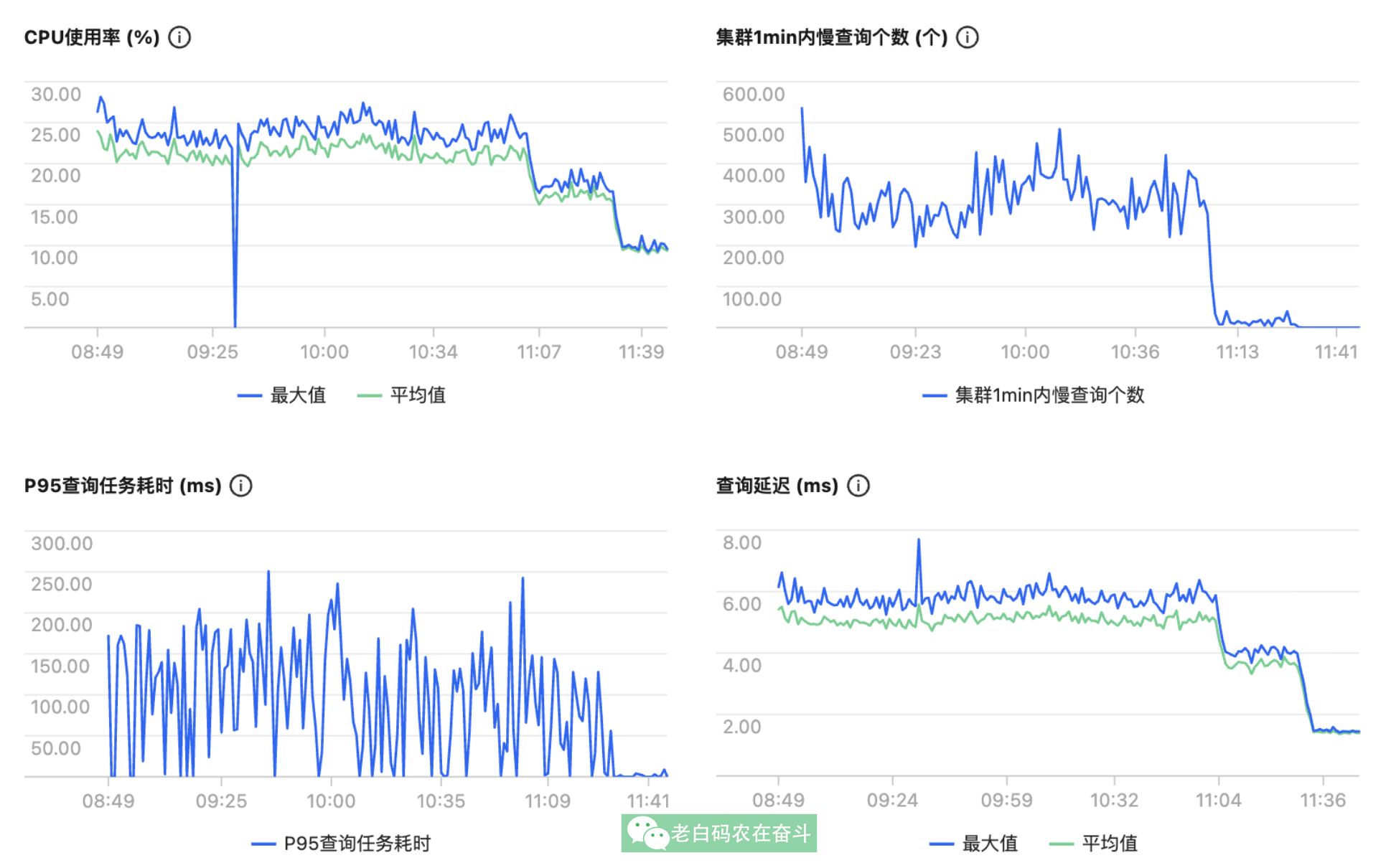
优化之后效果显著: CPU 使用率明显下降,慢查询降至0,耗时 P95 从 200ms~300ms 降至 10ms 以下。
为什么不替换 _seq_no
跟 Gemini 聊,它会建议把 _seq_no 改掉,使用 openid 等文档内部 keyword 作为 field。其出于以下考虑:
- 从工程方法论来看,
_seq_no属于“系统元数据”,它的设计目标是保证数据副本的一致性(通过primary_term和seq_no确认同步进度),而不是服务于业务逻辑。 - 不稳定性:它受底层存储引擎管理,业务层无法精准控制它的生命周期。另外,文档更新操作本质上是“删除 + 重新写入”,旧的
_seq_no会被标记为已删除,系统会给这个文档分配一个全新的、当前最大的_seq_no。一旦_seq_no变化,ES 就会认为分片“变新了”,之前的Request Cache全部失效。 - 性能瓶颈:由于它分散在不同的 Lucene Segment 中,大规模读取它作为哈希因子比读取普通的
Long字段要慢,因为它需要处理更多的元数据映射。
但是目前能使用的对应 doc 不变的,没有合适的 Long,有类似于 app_uuid 的字段。更换这个使用这个作为 field,时间大概接近原来的 4倍。这是因为 **_seq_no ** 是个 Long 类型的字段,占 8 字节,而 app_uuid 字段长度大概 36 字节,计算 hash 的时间也是增加约 4 倍。

工程上的反思
为什么上线之前没有压测出这个现象?
上线之前这个「高素质玩家」判断条件比较严苛,符合条件的 doc 比较少,因此每个请求的耗时会比较小。
而上线之后「高素质玩家」数量增加,当前查询条件的复杂度是 O(N) ,所以服务耗时也会线性相关的增加。
但是上线之前仍然有方法可以避免后续这样的问题出现——“防御式架构设计”:
- 考虑最坏的情况全是高质量玩家或者上百万的高质量玩家
- 使用 terminate_after 限制排序上限
- 上线之初就是用分桶,只不过一开始的条件是桶号 >0 即可,而后边慢慢的缩小成一个范围
很多工程师(包括资深开发者)在写代码时,习惯于实现功能:
我要随机选 32 个高质量用户,所以我写了
random_score。
但架构师的思维是:
我要随机选 32 个高质量用户。如果库里有 1 亿人,我的算法复杂度是多少?是 O(1)、O(log N) 还是 O(N)?