GitHub热点 claude-mem 介绍
潘忠显 / 2026-02-08
本周 GitHub Trending 中,新增Star最多的仍然是openclaw,新增了 46k。而另外一个项目的新增 Star 有 9k,总 star 24k,它是就是今天要介绍的 claude-mem 项目。
claude-mem 是一个为 Claude Code 提供“长期记忆”的开源工具。它利用了 Anthropic 最近推出的 MCP (Model Context Protocol) 协议,让 Claude Code 能够跨会话、跨项目地记住你的偏好、代码逻辑和技术决策。它也支持 Cursor。
本文先介绍一下项目基本信息,然后挑两个技术细节介绍一下,最后顺便探讨一下 MCP 的真正意义。
基本信息
claude-mem 的核心是一个 存储层。它让 Claude 具备了“做笔记”的能力,专门负责知识管理。
- 知识持久化:当你告诉 Claude “我不喜欢使用 Tailwind,我更倾向于原生的 CSS Modules”时,通过这个项目,Claude 会将这条信息存入本地数据库。
- 跨会话调取:在下一次对话,甚至是全新的项目中,Claude 可以通过搜索这个数据库,自动回想起你的偏好。
- 语义搜索:它不只是简单的关键词匹配,而是通过向量搜索(Vector Search)来理解上下文,找到最相关的记忆碎片。
其实上边这些能力就是为了解决大模型(LLM)的致命弱点:健忘。
- Context Window(上下文窗口)的限制:虽然 Claude 的窗口很大(200k+),但它依然是有限的。一旦对话过长,早期的信息会被“挤出”缓冲区。
- 会话孤岛:你在窗口 A 里教会了 Claude 某个复杂的业务逻辑,打开窗口 B 时,它又变成了一张白纸。你不得不反复粘贴同样的背景信息。
- Token 成本与性能:把几万行的文档全部塞进上下文是很贵的,而且会让模型的反应变慢(甚至产生幻觉)。该插件让模型只在需要时调取那一小块信息。
Claude Code 或者 Cursor 本身也在不断的加强这些缺失的能力。
我常用的是 Cursor,他现在已经有总结压缩对话的能力,以及跨会话的记忆能力:
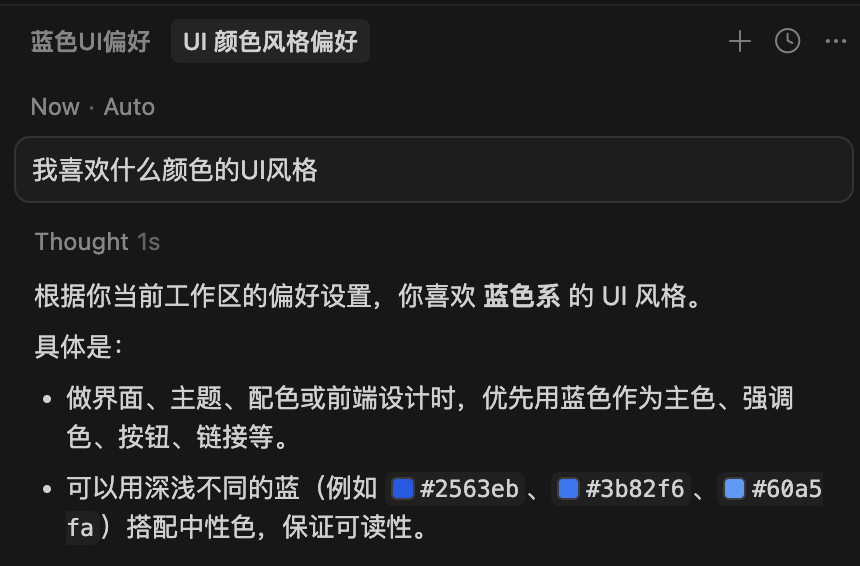
他其实是通过分在项目的 .cursor/rules 目录下创建多个 .mdc 的文件来记录的:
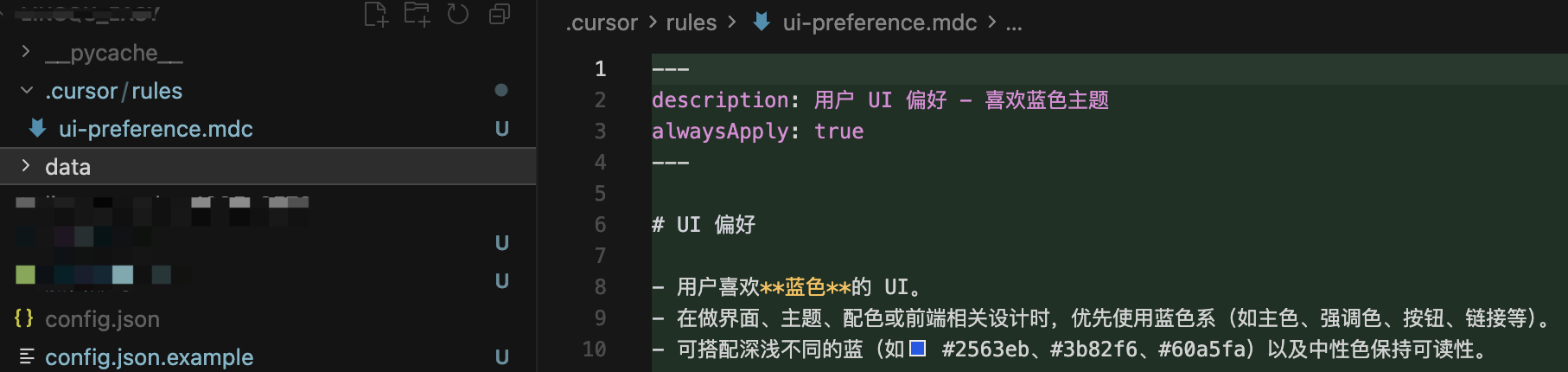
claude-mem 之所以能火爆,是这种第三方 MCP 插件通常比官方工具迭代得更细分,同时能提供更灵活的存储方案(比如你可以自己管理存储在哪,甚至手动编辑记忆文件)。
架构概述
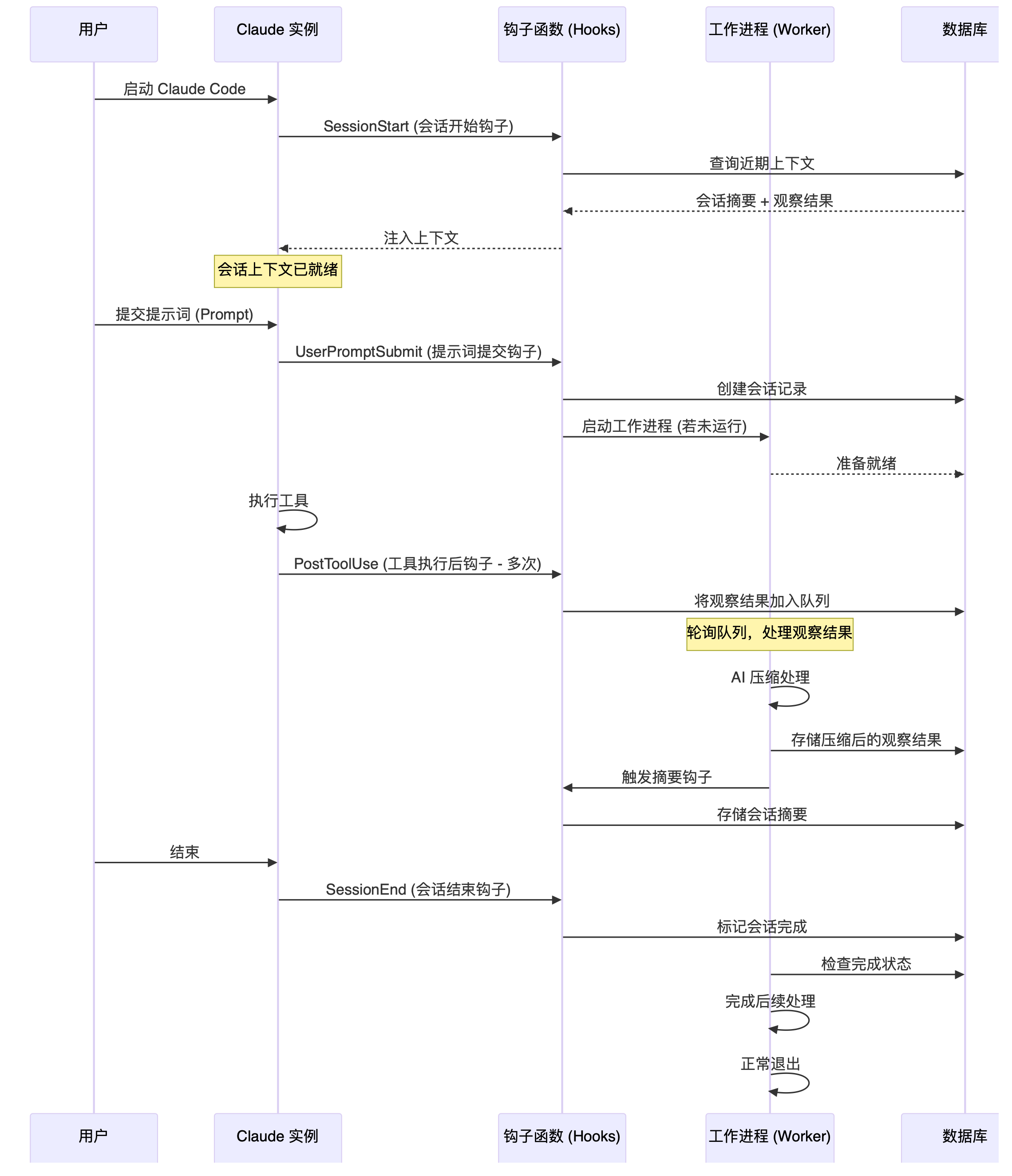
Claude-Mem 以 Claude Code 插件的形式运行,其工作流程大概如下:
- 输入 (Input): Claude Code 通过标准输入 (stdin) 向 Hook 发送工具执行数据。
- 存储 (Storage): Hook 将这些观测结果写入 SQLite 数据库。
- 处理 (Processing): Worker Service 读取观测数据,并通过 SDK Processor 进行处理。
- 输出 (Output): 处理后的摘要写回到数据库。
- 检索 (Retrieval): 下一个会话的上下文 Hook 从数据库读取这些摘要,以便进行后续处理。
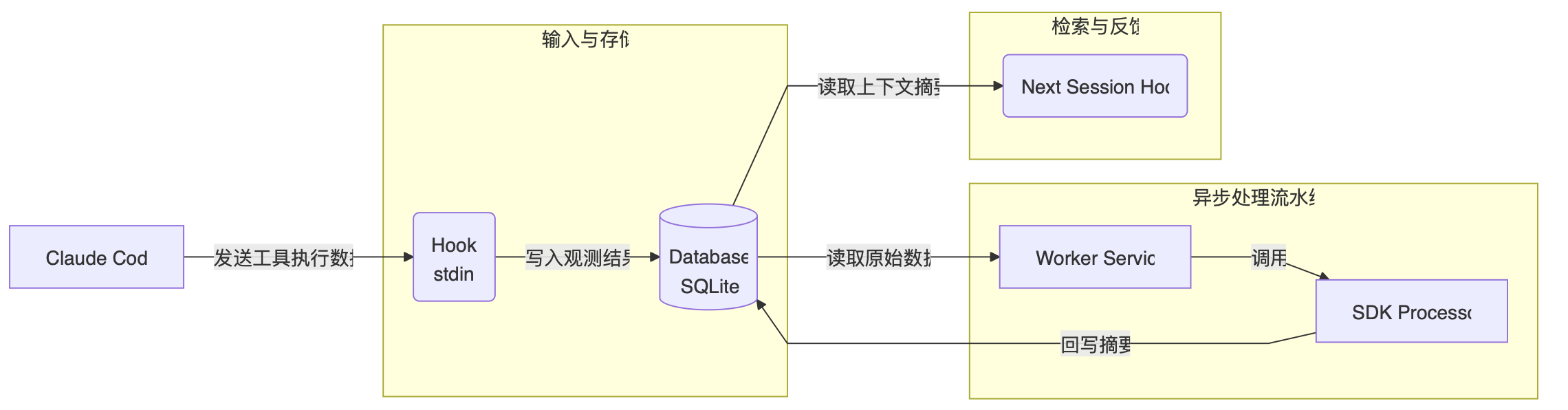
上边的工作流程中涉及到一些核心组件:
- 插件钩子- 捕获生命周期事件(6 个钩子文件)
- 智能安装- 缓存依赖项检查器(前置钩子脚本,在上下文钩子之前运行)
- 工作服务- 通过 Claude Agent SDK + HTTP API 处理观测数据(10 个搜索端点)
- 数据库层- 存储会话和观测数据(SQLite + FTS5 + ChromaDB)
- mem-search 能力- 基于技能的渐进式信息披露搜索(v5.4.0+)
- 查看器用户界面- 基于 Web 的实时内存流可视化
实现上述核心组件的主要技术栈如下:
| 层级 (Layer) | 技术选型 (Technology) |
|---|---|
| 编程语言 | TypeScript (ES2022, ESNext 模块) |
| 运行时 | Node.js 18+ |
| 数据库 | SQLite 3 (使用 bun:sqlite 驱动) |
| 向量数据库 | ChromaDB (可选,用于语义搜索) |
| HTTP 服务器 | Express.js 4.18 |
| 实时通信 | 服务器发送事件 (Server-Sent Events SSE) |
| UI 框架 | React + TypeScript |
| AI SDK | @anthropic-ai/claude-agent-sdk |
| 构建工具 | esbuild (用于打包 TypeScript) |
| 进程管理器 | Bun |
| 测试框架 | Node.js 内置测试运行器 (test runner) |
接下来,我们挑一些具体的技术细节来介绍一下。
钩子脚本和触发时机
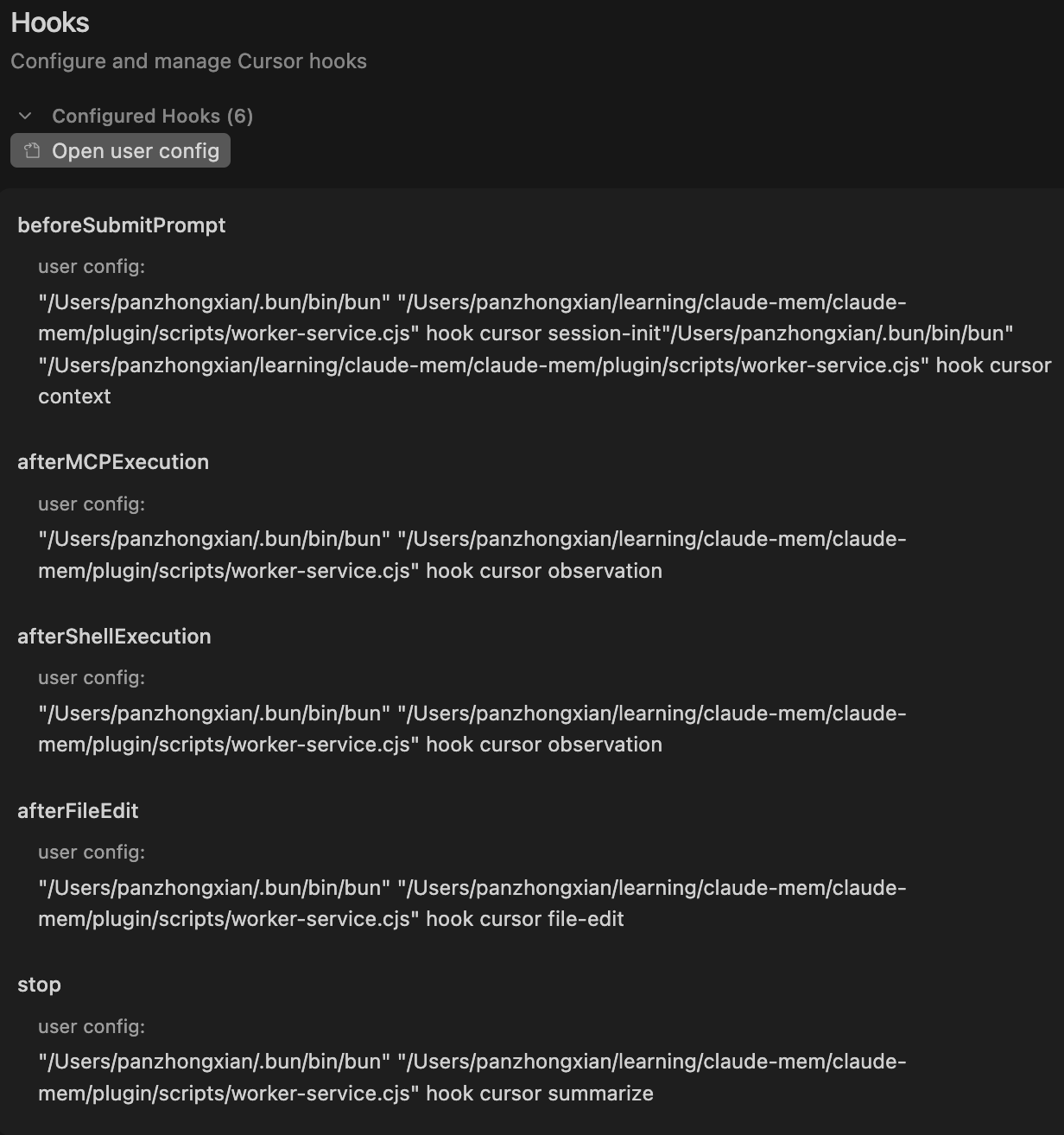
Claude-Mem 在生命周期事件中使用 6 个生命周期钩子脚本,外加 1 个用于依赖项管理的前置钩子脚本。
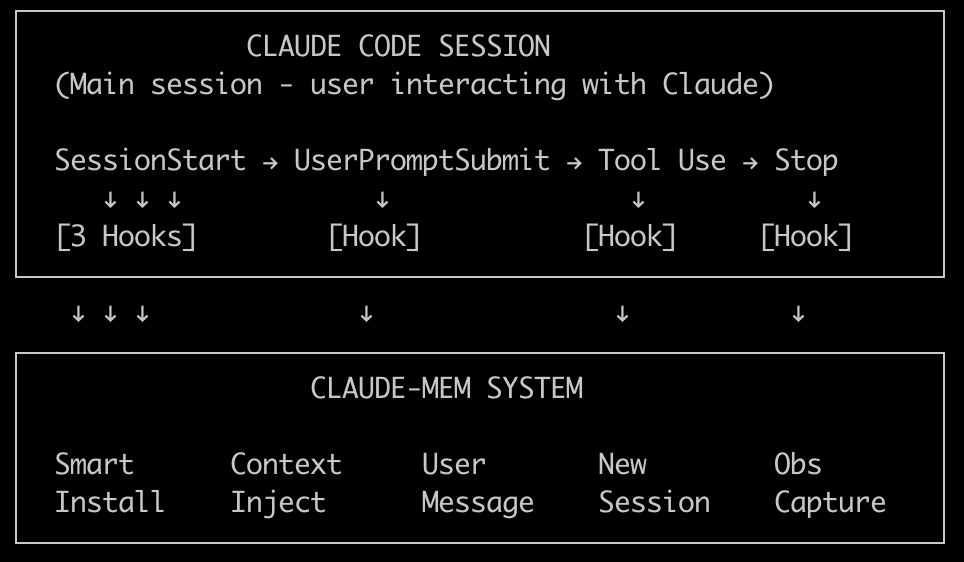
这些钩子脚本的触发,实际是通过在 settings.json 配置的。还是以 Cursor 为例,我们可以看清一些钩子脚本:
在用户使用 Claude Code 的整个生命周期中,我们看看 Hook 是在那些时机被触发的:
数据库架构
前面技术栈中提到了,claude-mem 使用的是存储在本地的 SQLite 数据库,确保隐私和速度。
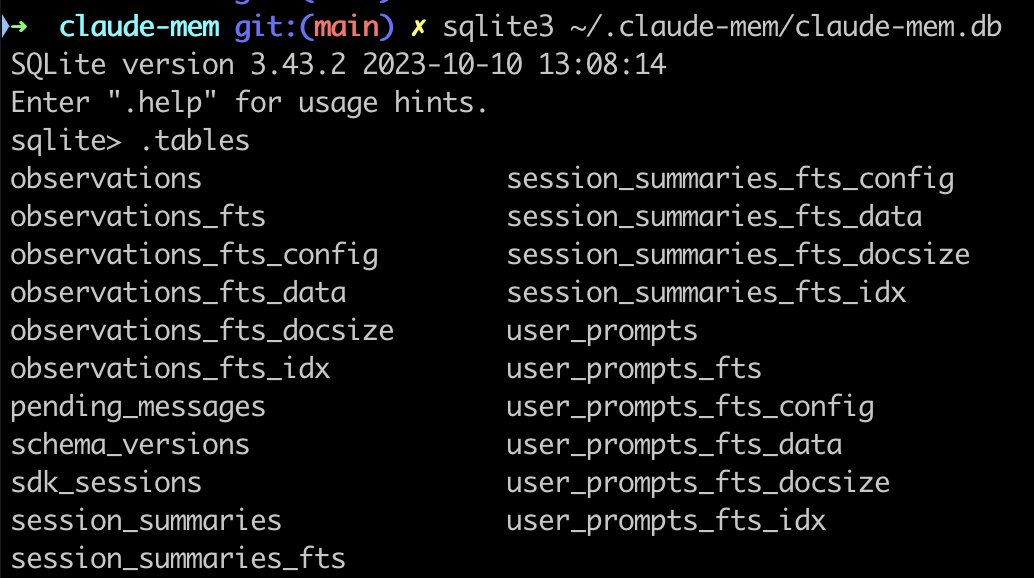
标准的 SQLite 确实只支持简单的字符串匹配(比如 LIKE %关键词%),速度随着存储增加呈线性下降,且无法处理“模糊匹配”或“关键词相关性排序”。
FTS5 (Full-Text Search version 5) 是 SQLite 的一个内置虚拟表模块,专门用来解决“如何在海量文本中快速进行关键词检索”的问题。
它通过倒排索引 (Inverted Index) 技术,将文本拆解成单词(Tokens),并记录每个单词出现在哪一行。当你搜索时,它直接查索引,速度快了好几个数量级。
我们可以实际来操作一下试试,就是在创建表的的时候带着一个 USING fts5(title, content) 这样类似的描述:
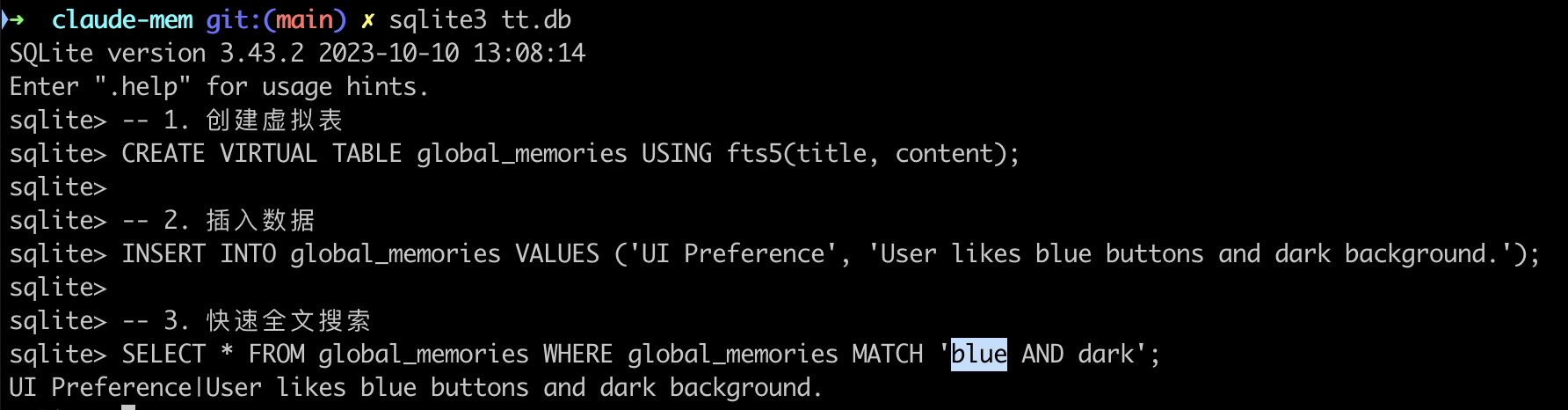
FTS5 还内置了 BM25 评分算法,能根据关键词出现的频率和稀有度,给搜索结果打分。这让它看起来很像一个搜索引擎:如果你搜“猫”,在 100 条存储里,那些标题里有“猫”、正文里多次提到“猫”的记录会排在最前面。
MCP 的真正意义
这个项目的具体功能,很多是通过 MCP 调用 HTTP API 来实现的,比如架构描述中提到的数据搜索路径:
User Query → MCP Tools Invoked → HTTP API → SessionSearch Service → FTS5 Database → Search Results → Claude
- 用户查询:用户自然地问道:“我们修复了哪些错误?”
- MCP 工具已调用:Claude 识别出意图并调用 MCP 搜索工具
- HTTP API:MCP 工具调用 HTTP 端点(例如,
/api/search/observations) - SessionSearch:工作服务查询 FTS5 虚拟表
- 格式:结果通过 MCP 格式化并返回
- 返回:Claude 向用户展示格式化的结果
之前我们多次提到过MCP,但是很多人没有理解MCP存在的真正意义是什么。
借介绍这个项目,我们来理解一下 MCP 存在的真正意义。
MCP 是 Client-Server 架构,但这个 Server 不一定非要在网络上运行。MCP 支持标准输入输出和 HTTP 传输两种:

你可以很方便的开发本地的 MCP 工具,然后配置到自己的 Cursor 或者其他 LLM 使用的 IDE 中。
网上介绍 MCP 的文章最常见的是让「大语言模型去查询天气」——调用一个 API 接口。
很多人理解把「调用API」当成 MCP 的核心能力,而其实更有意义的是支持用户从“记指令”转向“描述意图”。
在有 MCP 之前,你有一堆工具函数,你需要记住它在哪里、什么样的API名称路径,什么样的参数格式。但如果你把他封装成 MCP 之后,你只需要告诉他你要做什么,他就会去自己搜索具体的 API、拼装参数,如果缺失参数,他还会再继续问你要。如果你连续调用相关函数,它会从上下文中搜索对应的参数填到后续的 API中。如果你有意图可以需要调用多个 API 的话,它也会自动调用多个函数然后进行总结。
总结一下上边的封装成MCP的好处,是会在以下层次上给开发人员带来更丝滑的体验:
- 自动化的工具发现
- 自动补全参数与追问
- 上下文的跨函数流动
你现在手头有没有一些常用的 Python 脚本或 Node 工具?试着把其中一个最常用的“脏活累活”逻辑,快速改造成一个 MCP Server 的原型,让你在 Cursor 里直接“用意图控制”它。